Encoder-Free Human Motion Understanding
via Structured Motion Descriptions
Abstract
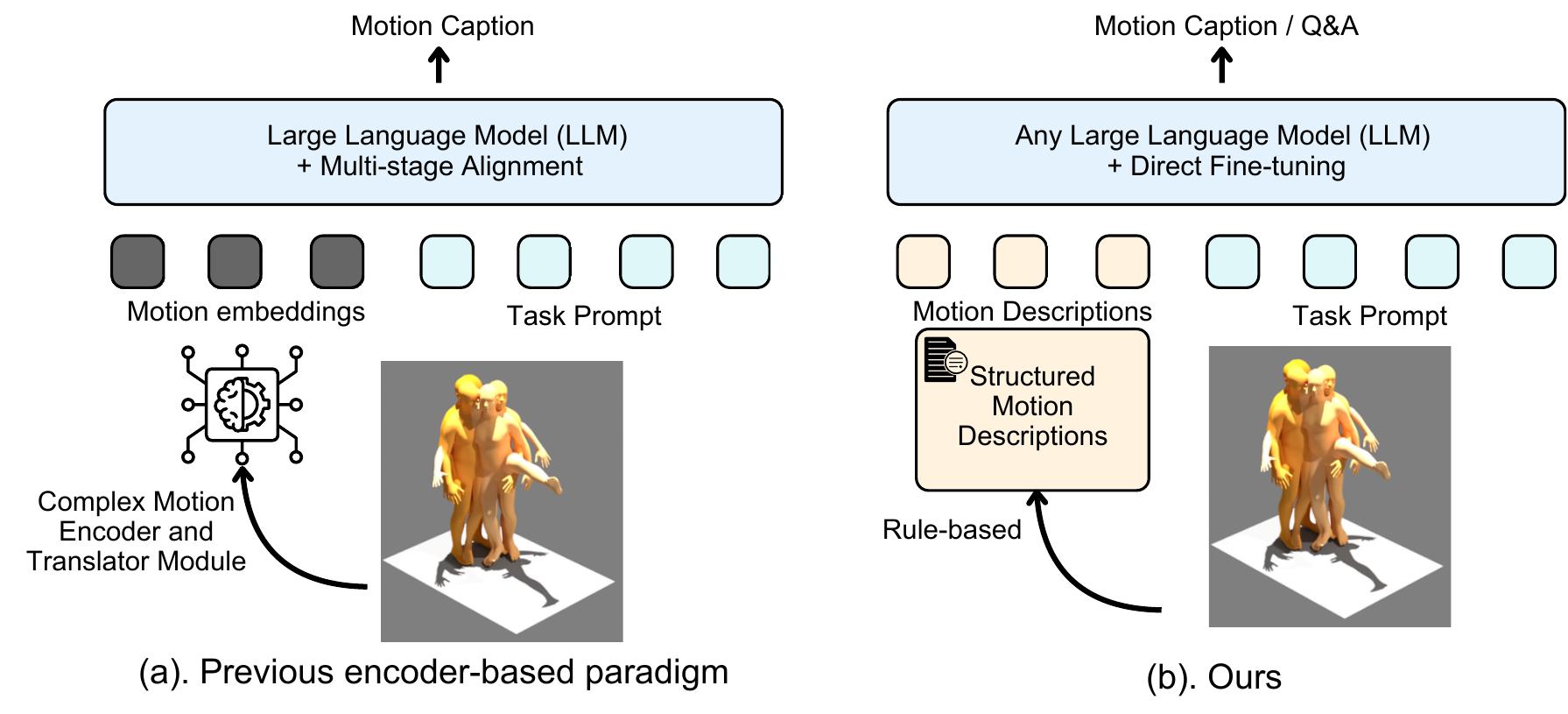
The world knowledge and reasoning capabilities of text-based large language models (LLMs) are advancing rapidly, yet current approaches to human motion understanding — including motion question answering and captioning — have not fully exploited these capabilities. Existing LLM-based methods typically learn motion–language alignment through dedicated encoders that project motion features into the LLM's embedding space, remaining constrained by cross-modal representation and alignment. Inspired by biomechanical analysis, where joint angles and body-part kinematics have long served as a precise descriptive language for human movement, we propose Structured Motion Description (SMD), a rule-based, deterministic approach that converts joint position sequences into structured natural language descriptions of joint angles, body-part movements, and global trajectory. By representing motion as text, SMD enables LLMs to apply their pretrained knowledge of body parts, spatial directions, and movement semantics directly to motion reasoning, without requiring learned encoders or alignment modules.
SMD goes beyond state-of-the-art results on both motion question answering (66.7% on BABEL-QA, 90.1% on HuMMan-QA) and motion captioning (R@1 = 0.584, CIDEr = 53.16 on HumanML3D), surpassing prior methods. The same text input works across different LLMs with only lightweight LoRA adaptation (validated on 8 LLMs from 6 model families), and its human-readable representation enables interpretable attention analysis over motion descriptions.
Method
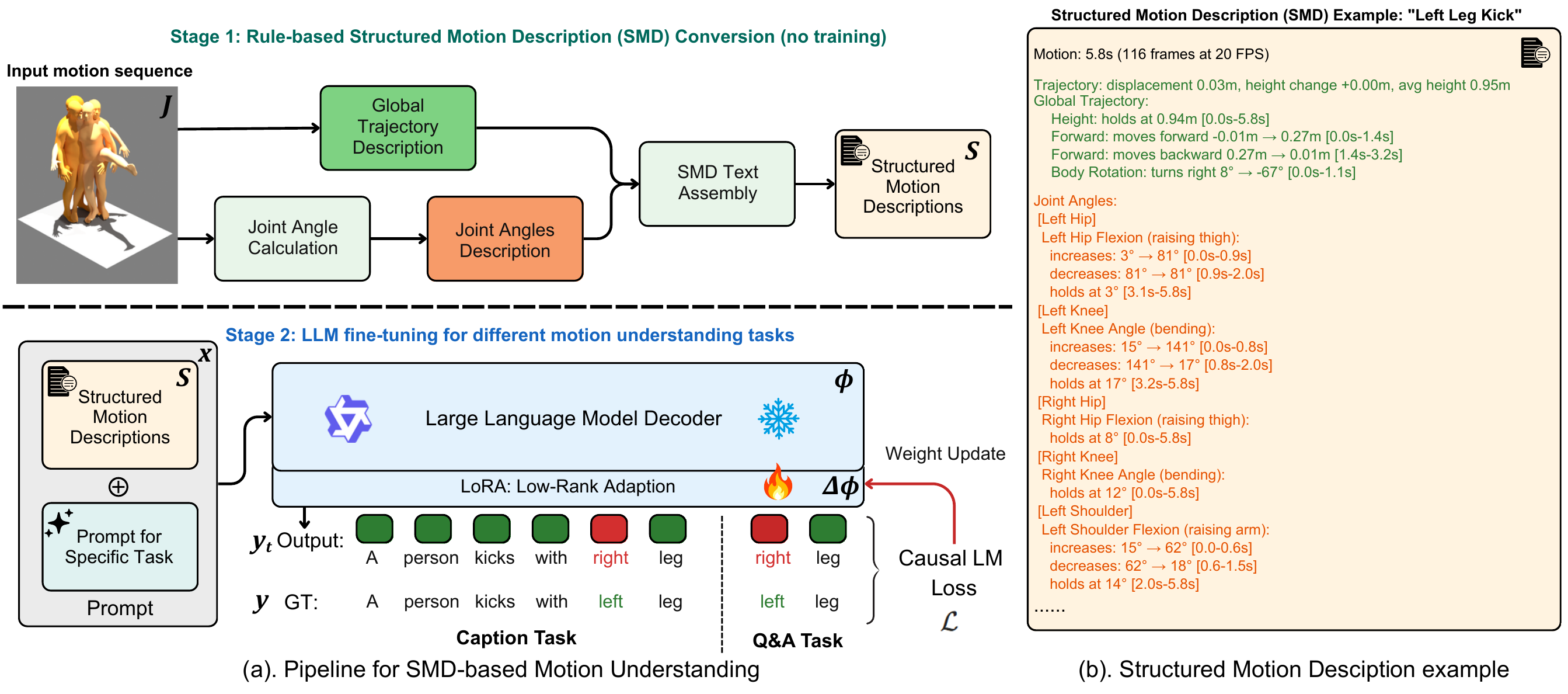
Example SMD
One real SMD from HumanML3D (Top-3 joint variant, ~1K tokens):
Motion: 7.0s (140 frames at 20 FPS)
Trajectory: displacement 0.01m, height change +0.00m, avg height 0.95m
Global Trajectory:
Height: static at 0.954m throughout
Forward Position: static at 0.001m throughout
Lateral Position: static at 0.002m throughout
Joint Angles:
[Right Shoulder]
Right Shoulder Flexion (raising arm forward):
holds at 3° [0.0s–3.4s] (3.4s)
increases: -1° → 84° [3.4s–4.5s]
holds at 82° [4.6s–5.5s] (0.9s)
...
More samples in the GitHub examples/ and the full 17 variants on the HuggingFace dataset repo.
Main Results
Motion Question Answering (accuracy %)
| Method | Input | Backbone | BABEL-QA ↑ | HuMMan-QA ↑ |
|---|---|---|---|---|
| IMoRe [Li et al., ICCV 2025] | joints | Specialized | 60.1 | 75.2 |
| MotionGPT3-Qwen (our controlled baseline) | VAE tokens | Qwen2.5-7B | 50.1 | 22.0 |
| SMD + Qwen2.5-7B (LoRA) | text | Qwen2.5-7B | 66.7 | 90.1 |
MotionGPT3-Qwen is a controlled baseline we constructed that replaces SMD with VAE-encoded motion tokens on the same Qwen2.5-7B backbone — isolating the contribution of the motion representation.
Motion Captioning on HumanML3D
| Method | R@1 ↑ | R@3 ↑ | MM-Dist ↓ | CIDEr ↑ | BERTScore ↑ |
|---|---|---|---|---|---|
| MotionGPT3 [Zhu et al., 2025] | 0.573 | 0.864 | 2.43 | 40.6 | 35.2 |
| SMD + Qwen2.5-7B (LoRA) | 0.584 | 0.883 | 2.35 | 53.16 | 45.58 |
See the paper for the complete tables, backbone-portability study across 8 LLMs, and ablations on trajectory / joint-count / segmentation variants.
Interpretability

Resources
- Code: github.com/yaozhang182/motion-smd
- Dataset (SMD texts + preprocessed QA + HumanML3D subset): huggingface.co/datasets/zyyy12138/motion-smd-data
- Models (LoRA adapters for 8 LLMs): huggingface.co/zyyy12138/motion-smd-lora
- Paper: arXiv:2604.21668